
At work, I was asked to write a custom diff tool—an in-house solution designed to detect and address code drift between two projects. While its primary focus was on these repos, I built it with a slightly broader scope in mind so it could diff other golang codebases as well. The option was either go or python, I chose to write it in python (I should have not).
What i’ll be talking about:
- what mimesis is and why it was needed
- how i approached it
- building it
- why it’s no longer needed
- alternatives to mimesis
What Mimesis Is and Why It Was Needed
Mimesis is a custom diffing tool I wrote in python to detect and address code discrepancies between two important repos in the old plugin architecture.
- Plugeth: A fork of the upstream Geth client, which frequently received updates.
- Plugeth-utils: small packages used to develop Plugeth plugins without Geth dependencies. It’s a utility repository providing types and interfaces that plugins relied on.
The need for mimesis arose because these two repos had to stay in sync for the plugins to work correctly. When plugins were built they relied on plugeth-utils to provide interfaces and types which correspond to interfaces and types in plugeth. As the upstream Geth client was updated, we merged those updates into our plugeth fork, this introduced an opportunity for the code in plugeth-utils to drift from plugeth.
This drift caused a couple of issues:
- Plugins failed to build/load properly, as mismatched types / interfaces caused plugins to break.
- Data acquisition from plugins became inconsistent.
- Subtle inconsistencies were often not immediately apparent, leading to headaches when tracking down where the divergence occurred or what cascading issues it introduced
These issues resulted in failures that were difficult to untangle, especially as updates accumulated over time. To address this I wrote mimesis to compare both repos, detect discrepancies in types, interfaces and functions and then output a report that could help devs identify and resolve discrepancies quickly (in plugeth-utils).
How I approached it
At first draft we (Philip and I) wrote a basic line-by-line parser in Python that searched for Go syntax patterns variables, types and functions. This version relied on pattern matching to identify code components and basic logic to determine where they started and ended. I.e:
- It searched for
{and}to find the boundaries of a struct or a function. - It manually compared extracted blocks of code between packages in
plugethandplugeth-utils.
At this stage, it was a proof of concept, a starting point to see how far we could get with minimal tooling. But this was clearly not enough and would not be reliable for complex types and more, it would even make a herculean task in trying to write for more cases.
ASTs & expanding the scope
We definitely could not rely on line-by-line parsing, so I looked into ASTs (Abstract Syntax Tree). An AST is a data structure that represents the structure of a program / source code as a tree.
With the Go AST, I could programmatically parse the structure of Go code into nodes and traverse it to extract it’s components. So I leveraged on Go’s inbuilt AST tools, go/ast and go/parser (at this point I should’ve probably ditched Python for Go). Instead I decided to use a wrapper that compiles these packages into a shared library and interfaces it with python.
While this started as a tool to solve a specific problem, I realised it had the potential to be more versatile. By handling all key components of a Go codebase —imports, declarations, types, struct fields, methods & functions etc) It could maybe serve as a general-purpose diff tool for Go devs facing similar alignment issues.
From here, I set out to write a program that could:
- Take in two repositories (control and source in this case plugeth & plugeth-utils).
- Parse their code into ASTs.
- Traverse the nodes and build models of the code for comparison.
Replacements
Before we embarked, we realised that certain discrepancies could arise not because of actual drift, but because of difference in naming, types and imports between repositories:
- One repository might use types or functions from a local package (e.g.,
core), while another uses equivalents from a shared package (e.g.,common). - Some types, methods, or utility functions might have been renamed or aliased for clarity, even though their functionality remains identical.
To handle this, we introduced a replacements.json configuration file. This file allows us to define mappings for replacing specific components with their counterparts. It ensures that when the program compares two repositories, it replaces specific types (or functions) before running the comparison. This step reduces noise in the diff output by focusing on actual discrepancies.
In our case, replacements were necessary because the restricted package in plugeth-utils relied on types and functions from the core package, which often had equivalents in plugeth’s common package. For example, types like core.Hash needed to be mapped to common.Hash, and utility functions like fromHex replaced with common.FromHex. Without this step, comparisons would flag legitimate dependencies as discrepancies, making the tool less accurate.
Building Mimesis
Once I decided on the approach for Mimesis, in my notes I highlighted three steps in bringing my hours of research into life. The last step was an afterthought, writing a GUI on it just so I could use it without interacting with it via the command line.
1. Parsing the Code
I wrote the program to take in either path to packages in the repo or path to single Go files.
if os.path.isdir(path):
for root, _, files in os.walk(path):
for file in files:
try:
if file.endswith(".go"):
file_path = os.path.join(root, file)
file_name = os.path.basename(file_path)
with open(file_path, "r") as f:
code = f.read()
if pathToReplacements:
mod_code = apply_replacements(code, pathToReplacements)
else:
mod_code = code
ast = goastpy.GoAst(mod_code).ast
Extract_node(ast, model, file_path)
# rest of the code...
elif os.path.isfile(path):
try:
with open(path, "r") as file:
code = file.read()
if pathToReplacements:
mod_code = apply_replacements(code, pathToReplacements)
else:
mod_code = code
ast = goastpy.GoAst(mod_code).ast
counter[0] += 1
ast_file_path = os.path.join(ast_path, f"model{counter[0]}.ast")
Extract_node(ast, model, path)
# rest of the code...
A Go AST

2. Extracting Nodes
After parsing Go source files into an AST, the next thing to do was to recursively traverse the AST and extract the components we cared about based off the nodeType
class Extract_node:
def __init__(self, node, model, file_path):
self.model = model
self.file_path = file_path
self.in_function = False # Tracks global/local types & variables
self.traverse_node(node)
def traverse_node(self, node):
if isinstance(node, dict):
node_type = node.get("_type")
if node_type == "FuncDecl": # Functions
self.extract_func(node)
elif node_type == "ImportSpec": # Imports
self.extract_imports(node)
elif node_type in {"GenDecl", "ValueSpec", "AssignStmt"}: # Types and Declarations
self.extract_vars_and_types(node)
for _, value in node.items():
if isinstance(value, (dict,list)):
self.traverse_node(value)
elif isinstance(node, list):
for item in node:
self.traverse_node(item)
Extracting Functions (FuncDecl)
I captured the names of the functions, its signatures (parameters and return values), any local variables or expressions used within the body.
def extract_func(self, node):
func_name = node.get("Name", {}).get("Name")
receiver_info = self.extract_receiver(node)
params = self.extract_function_params(node.get("Type", {}).get("Params", {}).get("List", []))
results = node.get("Type", {}).get("Results", {}).get("List", [])
return_types = (
[self.format_type(result.get("Type", {})) for result in results]
if results
else ["none"]
)
return_value = self.extract_return_value(node.get("Body", {}))
position = self.extract_position(node)
param_str = ", ".join([f"{param['name']} {param['type']}" for param in params])
return_str = ", ".join(return_types)
function_signature = f"{func_name}({param_str}) {return_str}"
func_data = {"name": func_name, "signature": function_signature, "return_val": return_value, "position": position,
"file_path": self.file_path, "local_types":[], "local_variables": []
}
if receiver_info:
method_signature = f"({receiver_info['name']} {receiver_info['type']}) {func_name}"
func_data["name"] = method_signature
self.model["methods"].append(func_data)
else:
self.model["funcs"].append(func_data)
self.local_types = []
self.local_variables = []
self.in_function = True
self.traverse_node(node.get("Body", {}))
self.in_function = False
func_data["local_types"] = self.local_types
func_data["local_variables"] = self.local_variables
Extracting Imports
def extract_imports(self, node):
import_path = node.get("Path", {}).get("Value")
if import_path:
self.model["imports"].append(import_path)
Extracting Types
I’m iterating over each specification in the node’s “Specs” list, and extracting the types on it’s category: InterfaceTypes, StructType, ArrayType and Ident
if node.get('Tok') == 'type':
for spec in node.get("Specs", []):
type_name = spec.get('Name', {}).get('Name')
type_category = spec.get("Type", {}).get("_type")
type_methods = []
type_fields = []
position = self.extract_position(node)
element_type = None
if type_category == "InterfaceType":
type_methods = [{"name": (method.get("Names")[0].get("Name") if method.get("Names") else None),
"signature": f"{method.get('Names')[0].get('Name') if method.get('Names') else method.get('_type', 'Unknown')}{self.format_method_signature(
method.get('Type', {}).get('Params', {}).get('List', []),
method.get('Type', {}).get('Results', {}).get('List', []))}"
}
for method in spec.get("Type", {}).get("Methods", {}).get("List", [])
]
elif type_category == "StructType":
type_fields = [{
"field_name": (
field.get("Names")[0].get("Name") if field.get("Names") else None),
"field_type": self.format_type(field.get("Type", {})),
} for field in spec.get("Type", {}).get("Fields", {}).get("List", [])]
elif type_category == "ArrayType":
type_elt = spec.get("Type", {}).get("Elt", {})
formatted_type_elt = self.format_type(type_elt)
element_type = f"[]{formatted_type_elt}"
elif type_category == "Ident":
element_type = spec.get("Type", {}).get("Name")
if type_name and type_category:
type_info = {
"name": type_name,
"type": type_category,
"methods": type_methods,
"field": type_fields,
"element_type": element_type,
}
if self.in_function and self.model['funcs']:
start_line = spec.get("Loc", {}).get("Start", {}).get("Line")
type_info["line"] = start_line
self.local_types.append(type_info)
else:
type_info['position'] = position
type_info['file_path'] = self.file_path
self.model['types'].append(type_info)
Extracting variables
We check if if the Tok (token) attribute of a node is either ‘var’ or ‘const’ to identify a var or const declarations, Or whether it’s a short variable := and extract the name and it’s value.
elif node.get('Tok') in {'var', 'const'}:
for spec in node.get('Specs', []):
if spec.get('_type') == 'ValueSpec':
var_type = self.format_type(spec.get("Type", {}))
value_nodes = spec.get("Values", [])
value = self.format_value(value_nodes[0]) if value_nodes else None
position = self.extract_position(spec)
for name in spec.get("Names", []):
var_name = name.get("Name")
var_info={
"name": var_name,
"type": var_type,
"value": value
}
if self.in_function and self.model['funcs']:
start_line = spec.get("Loc", {}).get("Start", {}).get("Line")
var_info['line'] = start_line
self.local_variables.append(var_info)
else:
var_info['position'] = self.extract_position(node)
var_info['file_path'] = self.file_path
self.model['variables'].append(var_info)
elif node.get('_type') == 'AssignStmt' and node.get('Tok') == ':=':
for lhs, rhs in zip(node.get('Lhs', []), node.get('Rhs', [])):
if lhs.get('_type') == 'Ident':
var_name = lhs.get('Name')
value = self.format_value(rhs)
var_info = {
'name': var_name,
'value': value,
}
if self.in_function and self.model['funcs']:
start_line = node.get("Loc", {}).get("Start", {}).get("Line")
var_info['line'] = start_line
self.local_variables.append(var_info)
else:
var_info['position'] = self.extract_position(node)
var_info['file_path'] = self.file_path
self.model['variables'].append(var_info)
Formatting Nodes
“Raw” AST nodes can be verbose and inconsistent. So I had to write helper functions to format types, expressions, struct fields, and values into a consistent readable structure. So we could use the model to perform meaningful comparisons.
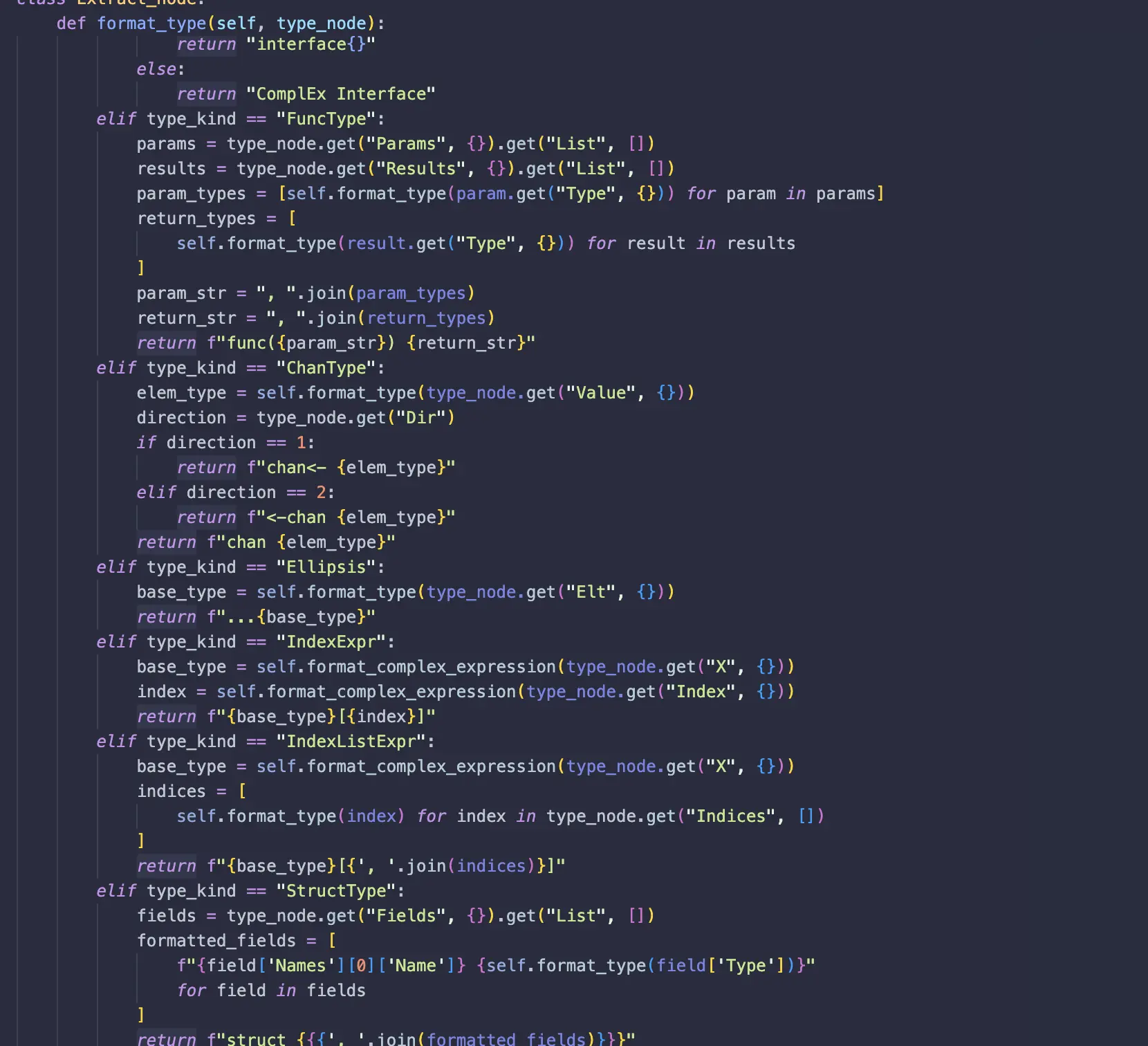
1. format_type
Formats Go types into clean, readable strings, including identifiers, arrays, and selectors.
Example:
Input AST Node:
{ "_type": "ArrayType", "Elt": { "_type": "Ident", "Name": "big.Int" } }
Formatted Output: []big.Int
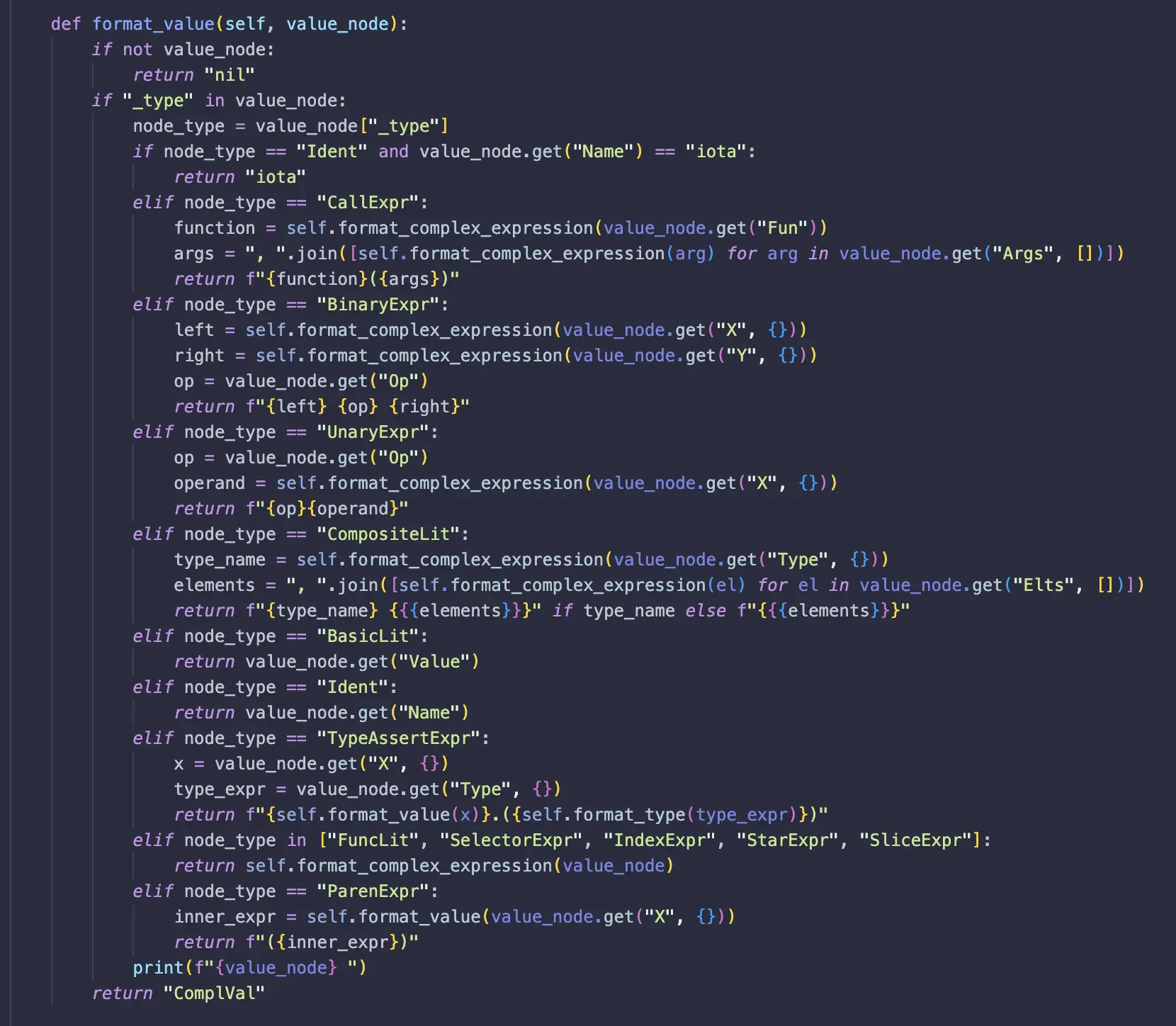
2. format_value
Formats values for variable declarations and assignments. It handles literals, selectors, function calls, and composite values.
Example:
Input AST Node:
{
"_type": "CallExpr",
"Fun": { "_type": "SelectorExpr", "X": { "Name": "crypto" }, "Sel": { "Name": "Sign" } },
"Args": [
{ "_type": "Ident", "Name": "h" },
{ "_type": "Ident", "Name": "prv" }
]
}
Formatted Output: crypto.Sign(h, prv)
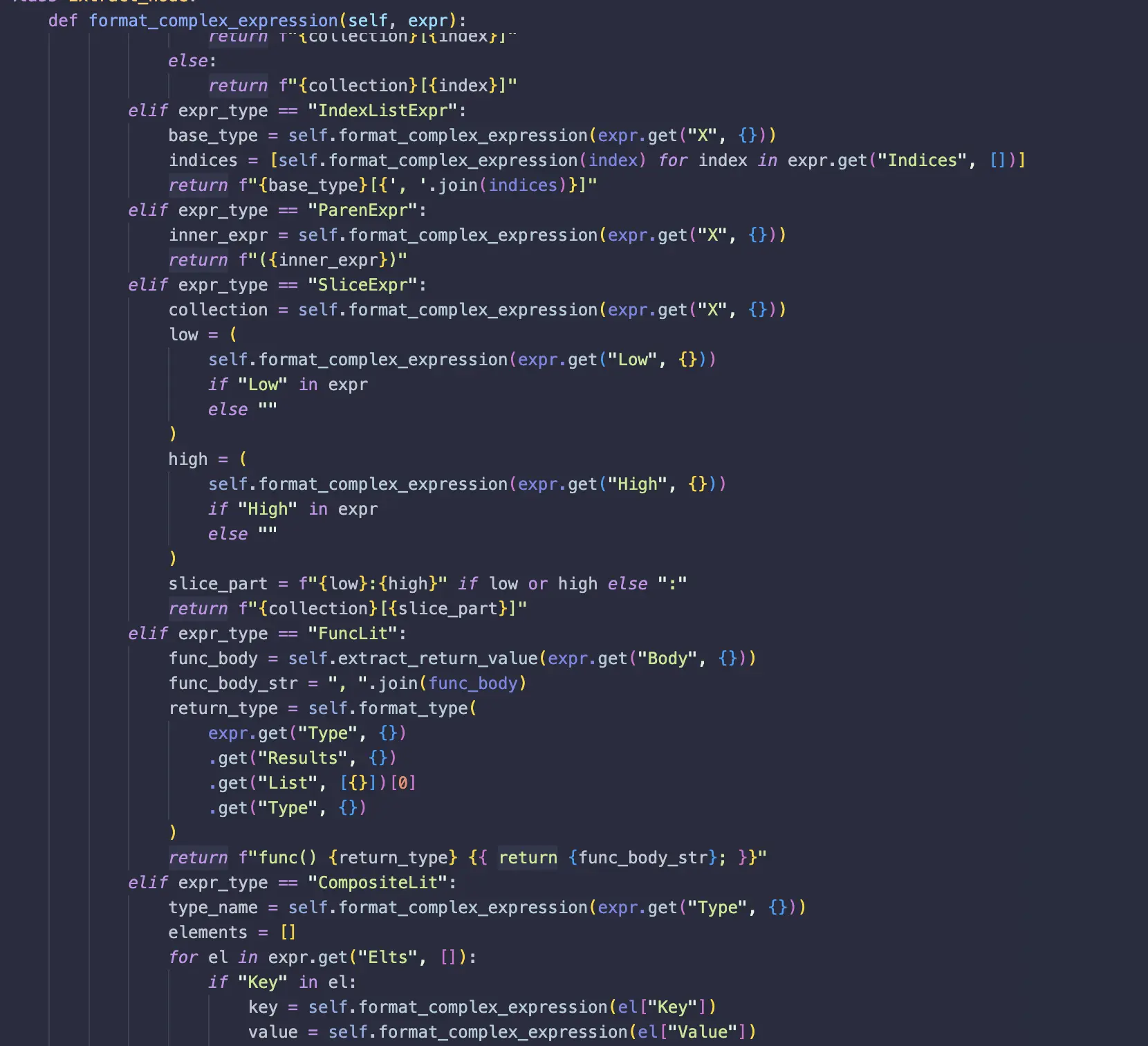
3. format_complex_expression
Recursively formats complex expressions like selectors, index expressions, function calls, and binary operations.
Example:
Input AST Node:
{
"_type": "BinaryExpr",
"Op": "+",
"X": { "_type": "Ident", "Name": "a" },
"Y": { "_type": "Ident", "Name": "b" }
}
Formatted Output: a + b
4. format_field_init
Formats struct field initializations or key-value pairs.
Example:
Input AST Node:
{
"Names": [{ "Name": "Hash" }],
"Values": [{ "_type": "SelectorExpr", "X": { "Name": "common" }, "Sel": { "Name": "Hash" } }]
}
Formatted Output: Hash: common.Hash
5. format_method_signature
Formats method or function signatures by combining parameters and return types into a clean string.
Example:
Input AST Node:
{
"Params": [{ "Names": [{ "Name": "tx" }], "Type": { "_type": "Ident", "Name": "Transaction" } }],
"Results": [{ "Type": { "_type": "Ident", "Name": "error" } }]
}
Formatted Output: (tx Transaction) error
6. format_method_return_types
Formats return types of functions or methods into a clean string, handling multiple return values.
Example:
Input AST Node:
{
"Results": [
{ "Type": { "_type": "Ident", "Name": "*Transaction" } },
{ "Type": { "_type": "Ident", "Name": "error" } }
]
}
Formatted Output: (*Transaction, error)
3. Comparing Models & JSON Output
Once the relevant nodes (functions, types, variables, and imports) were extracted and formatted, the next step was to: a) Build structured JSON models of the two repositories, b) Compare the models to identify discrepancies and c) Generating a json file that showed the discrepancies with enough details.
a) Building the JSON Models
After the program extracted and formated the components, It serialized the data into a structured JSON model. Each JSON file represented a snapshot of each package/ file, capturing every crucial code element.
Example model structure:
{
"funcs": [
{
"name": "MakeSigner",
"signature": "MakeSigner(config *params.ChainConfig, blockNumber *big.Int, blockTime *hexutil.Uint64) Signer",
"return_val": [
"signer"
],
"position": {
"start": 40,
"end": 57
},
"file_path": "pathToPlugeth/core/types/transaction_signing.go",
"local_types": [],
"local_variables": [
{
"name": "signer",
"type": "Signer",
"value": null,
"line": 41
}
]
}],
"methods": [
{
"name": "(s cancunSigner) Sender",
"signature": "Sender(tx *Transaction) core.Address, error",
"return_val": [
"s.londonSigner.Sender(tx)",
"core.Address {}",
"fmt.Errorf(\"%w: have %d want %d\", ErrInvalidChainId, tx.ChainId(), s.chainId)",
"recoverPlain(s.Hash(tx), R, S, V, true)"
],
"position": {
"start": 183,
"end": 195
},
"file_path": "pathToPlugeth/core/types/transaction_signing.go",
"local_types": [],
"local_variables": [
{
"name": "V",
"value": "tx.RawSignatureValues()",
"line": 187
}
]
}],
"variables": [
{
"name": "val",
"value": "*hexutil.Uint64(*tx.YParity)",
"position": {
"start": 64,
"end": 64
},
"file_path": "pathToPlugeth/core/types/transaction_marshalling.go"
}],
"types": [
{
"name": "Signer",
"type": "InterfaceType",
"methods": [
{
"name": "Sender",
"signature": "Sender(*Transaction) (core.Address, error)"
},
{
"name": "SignatureValues",
"signature": "SignatureValues(*Transaction, []byte) (*big.Int, error)"
},
{
"name": "ChainID",
"signature": "ChainID() (*big.Int)"
},
{
"name": "Hash",
"signature": "Hash(*Transaction) (core.Hash)"
},
{
"name": "Equal",
"signature": "Equal(Signer) (bool)"
}
],
"field": [],
"element_type": null,
"position": {
"start": 154,
"end": 169
},
"file_path": "pathToPlugeth/core/types/transaction_signing.go"
},
{
"name": "cancunSigner",
"type": "StructType",
"methods": [],
"field": [
{
"field_name": null,
"field_type": "londonSigner"
}
],
"element_type": null,
"position": {
"start": 171,
"end": 171
},
"file_path": "pathToPlugeth/core/types/transaction_signing.go"
},
{
"name": "Transactions",
"type": "ArrayType",
"methods": [],
"field": [],
"element_type": "[]*Transaction",
"position": {
"start": 542,
"end": 542
},
"file_path": "pathToPlugeth/core/types/transaction.go"
},
{
"name": "TxByNonce",
"type": "Ident",
"methods": [],
"field": [],
"element_type": "Transactions",
"position": {
"start": 598,
"end": 598
},
"file_path": "pathToPlugeth/core/types/transaction.go"
},
b) Comparing the Models
To compare the two JSON models, I wrote some code to that iterated through each section of the models (types, variables, functions, etc.) and identified mismatches. It applied replacements (defined in the replacements.json) before comparison to account for the aliasing I mentioned before.
The deep_compare_dict function recursively compares the two models (dictionaries). It skips certain keys like “file_path”, “line”, “position”, and “return_val”. If a key exists in both dictionaries, it checks if the values are dictionaries, lists, or other types and compares them accordingly.
def compare(model1, model2):
def deep_compare_dict(dict1, dict2, mismatches):
for key in dict1:
if key in {"file_path", "line", "position", "return_val"}:
continue
if key in dict2:
if isinstance(dict1[key], dict) and isinstance(dict2[key], dict):
deep_compare_dict(dict1[key], dict2[key], mismatches)
elif isinstance(dict1[key], list) and isinstance(dict2[key], list):
if key == "field":
compare_fields(dict1[key], dict2[key], mismatches, key)
elif key == "methods":
compare_methods(dict1[key], dict2[key], mismatches, key)
elif key == "local_variables":
compare_local_variables(dict1[key], dict2[key], mismatches, key)
elif key == "local_types":
compare_local_types(dict1[key], dict2[key], mismatches, key)
elif len(dict1[key]) == len(dict2[key]):
for i in range(len(dict1[key])):
if isinstance(dict1[key][i], dict) and isinstance(dict2[key][i], dict):
deep_compare_dict(dict1[key][i], dict2[key][i], mismatches)
elif dict1[key][i] != dict2[key][i]:
mismatches.append({key: [dict1[key][i], dict2[key][i]]})
else:
mismatches.append({key: [dict1[key], dict2[key]]})
elif dict1[key] != dict2[key]:
mismatches.append({key: [dict1[key], dict2[key]]})
c) Generating a JSON file
After comparing all the key code elements, the results are serialized into a JSON output that highlights discrepancies.
keys = set(model1.keys()).intersection(model2.keys())
results = {}
for k in keys:
if k == "imports":
continue
else:
key_value_1 = {subkey["name"]: subkey for subkey in model1[k]}
key_value_2 = {subkey["name"]: subkey for subkey in model2[k]}
mismatches = compare_key_value_pairs(key_value_1, key_value_2)
if mismatches:
results[k] = mismatches
with open('results.json', 'w') as res:
json.dump(results, res, indent=4)
return results
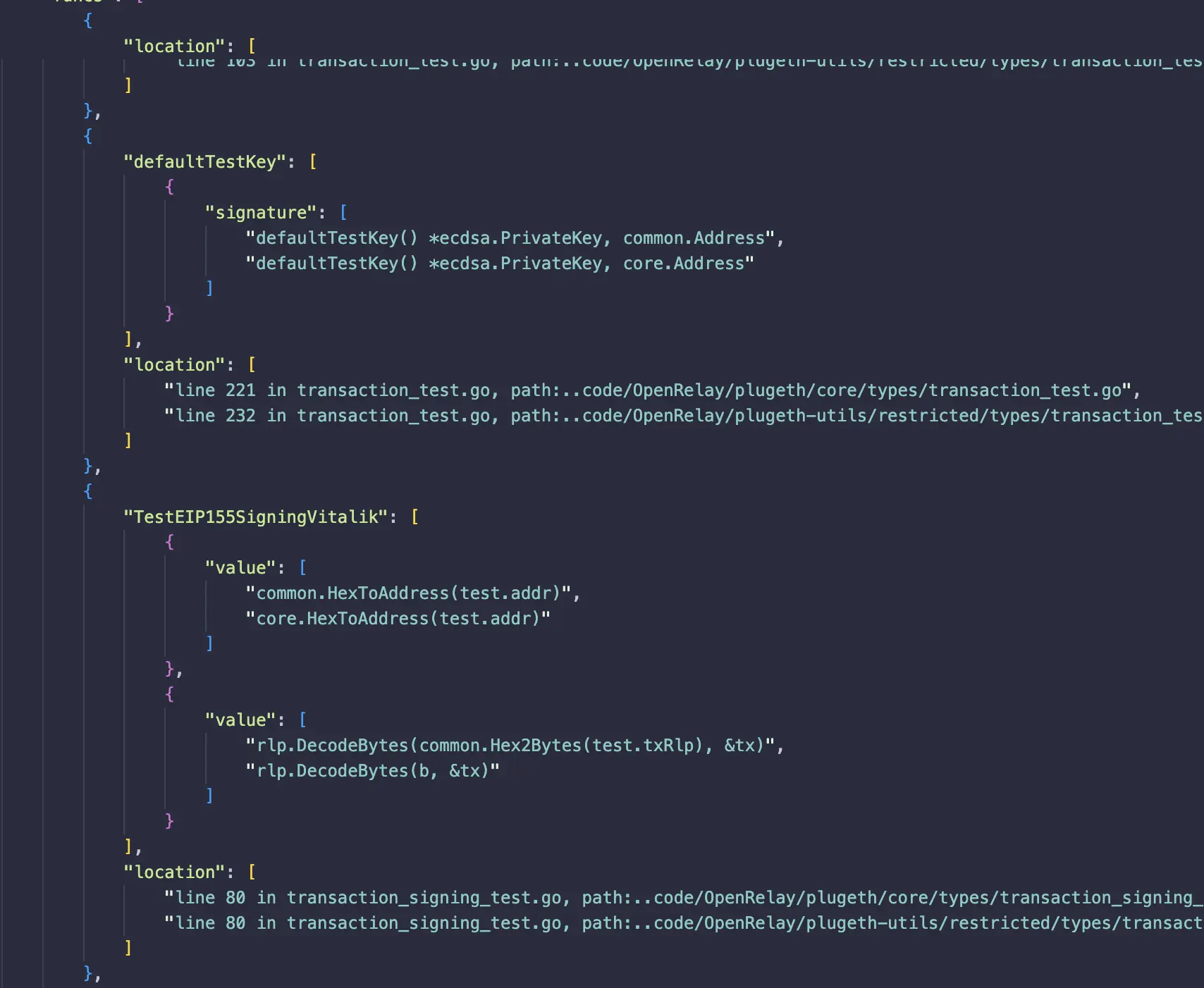
Example output after comparing the source and control models. results.json
{
"types": [
{
"StateDB": [
{
"field_type": ["atomic.Int64", "int"]
},
{
"field_type": ["atomic.Int64", "int"]
},
{
"field_type": ["map[common.Address]*stateObject", "map[common.Address]*types.StateAccount"]
}
],
"location": [
"line 81 in statedb.go, path:./plugeth/core/state/statedb.go",
"line 60 in statedb.go, path:../plugeth-utils/core/state/statedb.go"
]
}
],
"methods": [
{
"(s *StateDB) SubBalance": [
{
"signature": [
"SubBalance(addr common.Address, amount *uint256.Int, reason tracing.BalanceChangeReason) none",
"SubBalance(addr common.Address, amount *uint256.Int) none"
]
}
],
"location": [
"line 421 in statedb.go, path:./plugeth/core/state/statedb.go",
"line 383 in statedb.go, path:./plugeth-utils/core/state/statedb.go"
]
}
],
"funcs": [
{
"New": [
{
"signature": [
"New(root common.Hash, db Database) *StateDB, error",
"New(root common.Hash, db Database, snaps *snapshot.Tree) *StateDB, error"
]
},
{
"value": [
"&StateDB {db: db, trie: tr, originalRoot: root, reader: reader, stateObjects: make(map[common.Address]*stateObject), stateObjectsDestruct: make(map[common.Address]*stateObject), mutations: make(map[common.Address]*mutation), logs: make(map[common.Hash][]*types.Log), preimages: make(map[common.Hash][]byte), journal: newJournal(), accessList: newAccessList(), transientStorage: newTransientStorage()}",
"&StateDB {db: db, trie: tr, originalRoot: root, snaps: snaps, accounts: make(map[common.Hash][]byte), storages: make(map[common.Hash]map[common.Hash][]byte), accountsOrigin: make(map[common.Address][]byte), storagesOrigin: make(map[common.Address]map[common.Hash][]byte), stateObjects: make(map[common.Address]*stateObject), stateObjectsPending: make(map[common.Address]struct {}), stateObjectsDirty: make(map[common.Address]struct {}), stateObjectsDestruct: make(map[common.Address]*types.StateAccount), logs: make(map[common.Hash][]*types.Log), preimages: make(map[common.Hash][]byte), journal: newJournal(), accessList: newAccessList(), transientStorage: newTransientStorage(), hasher: crypto.NewKeccakState()}"
]
}
],
"location": [
"line 164 in statedb.go, path:../plugeth/core/state/statedb.go",
"line 143 in statedb.go, path:../plugeth-utils/core/state/statedb.go"
]
}
],
"variables": [
{
"slots": [
{
"value": ["s.deleteStorage(addr, addrHash, prev.Root)", null]
}
],
"location": [
"line 1076 in statedb.go, path:./plugeth/core/state/statedb.go",
"line 1038 in statedb.go, path:./plugeth-utils/core/state/statedb.go"
]
},
{
"err": [
{
"value": [
"db.Update(ret.root, ret.originRoot, block, ret.nodes, set)",
"s.db.TrieDB().Update(root, origin, block, nodes, set)"
]
}
],
"location": [
"line 1302 in statedb.go, path:../plugeth/core/state/statedb.go",
"line 1280 in statedb.go, path:../plugeth-utils/core/state/statedb.go"
]
}
]
}
Going back to the initial problem that birthed this —with this result output from mimesis, we can see discrepancies between the code in plugeth and plugeth-utils here. Take the first result, the type StateDB , the type of it’s fields don’t tally. The top being the control (plugeth), bottom being the source (plugeth-utils).
{
"field_type": [
"atomic.Int64", // control
"int" // source
]
},
{
"field_type": [
"map[common.Address]*stateObject", // control
"map[common.Address]*types.StateAccount" // source
]
}
4. The GUI
I wrote this with customTkinter so “we” could easily add files and packages, run the diff and view the results & download it. It felt nice to have and I found it easier to use.
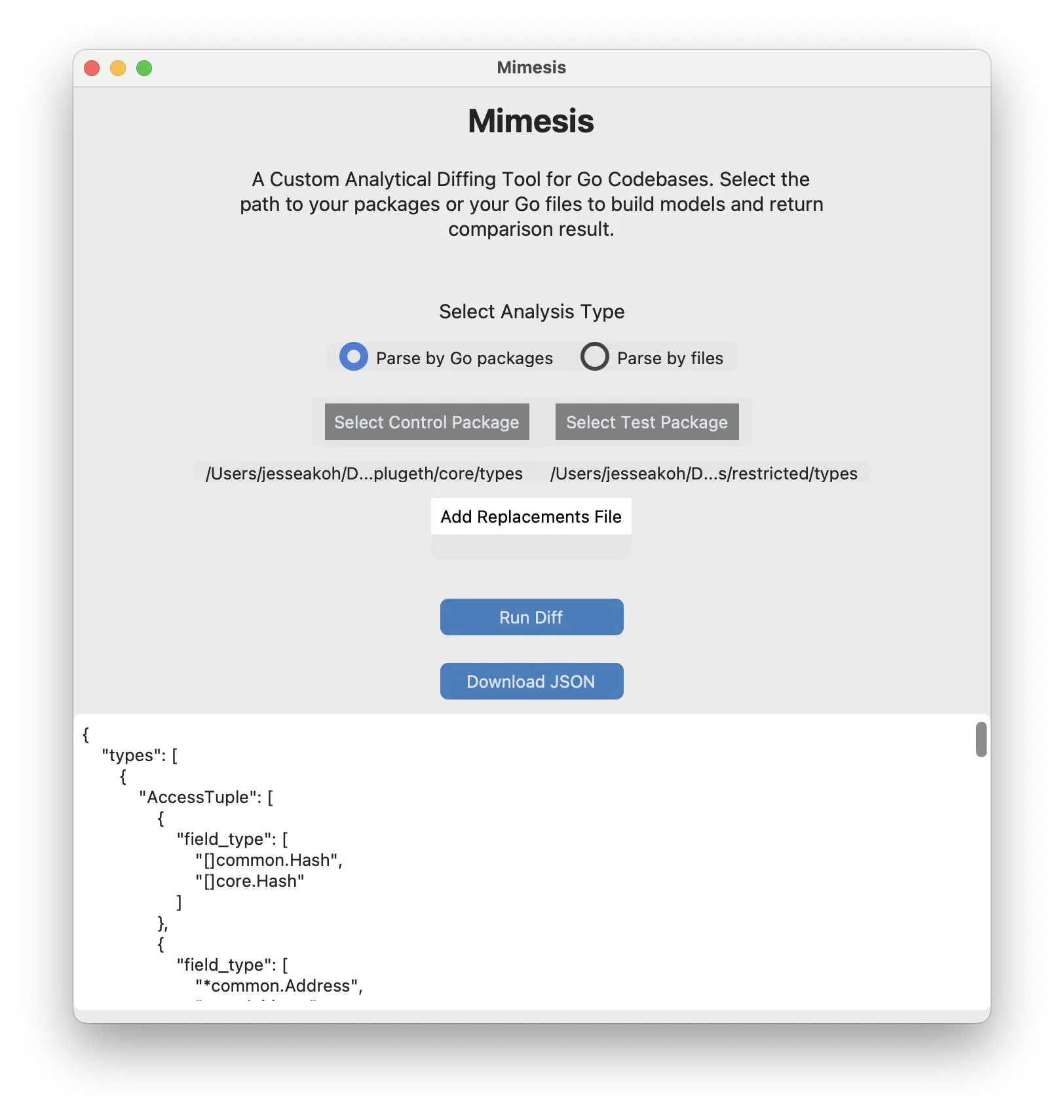
Why It’s No Longer Needed
While Mimesis successfully addressed a critical problem, it’s no longer needed because the plugin architecture was redesigned which now eliminates the root causes of code drift. The new system integrates a build tool that applies controlled patchsets to ensure the Geth client and modifications (such as hooks and injections) remain consistent. Automated tests are now part of the build process, aligning and validating changes ‘proactively’ at build time. This shift removes the need for a tool like Mimesis to compare code across repositories.
Alternatives to Mimesis
Instead of relying on post-hoc comparisons, we could have:
- Automated Validation Tests: Use Go’s
go/astto programmatically check that types, interfaces, and functions remain consistent between repositories. - Pre-Merge Hooks: Enforce alignment checks before changes to
plugethare merged, ensuring updates are validated early. - Controlled Patch Management: Systematically apply and track upstream changes to
plugeth-utilsusing patches generated fromgit diff.
This workflow would have proactively prevented the drift, eliminating the need for Mimesis altogether.
https://cs.opensource.google/go/go/+/master:src/go/ast/ast.go
https://github.com/itayg25/goastpy
https://dev.to/balapriya/abstract-syntax-tree-ast-explained-in-plain-english-1h38